
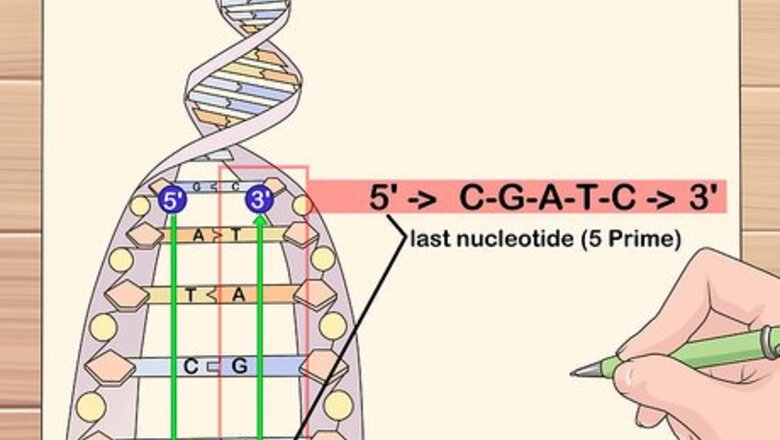
By Hand
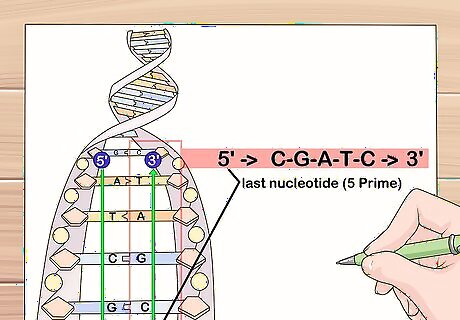
Trace through the sequence backwards, starting from the last nucleotide in the sequence.
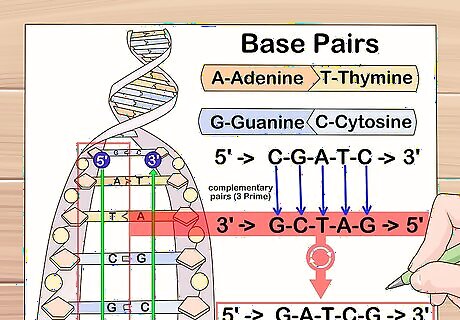
As you pass over each nucleotide, add its complementary nucleotide to the next line, beginning the complemented string from the left-hand side of the page. Remember, guanine (G) bonds to cytosine (C) and adenine (A) bonds to thymine (T).
Programmatically (Python 2)

Create or accept an input file. This article assumes that the input is in FASTA format, with a single sequence per file. The following steps also assume that all nucleotides are ATGC bases.
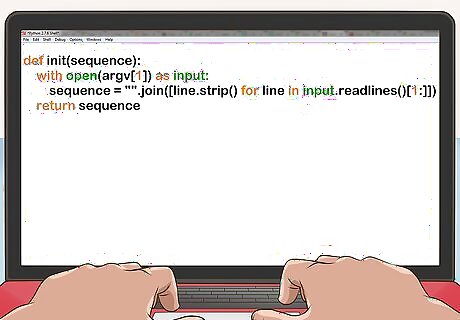
Read in the file. For FASTA format: Discard the first line of the file. Remove all remaining newlines and other trailing whitespace. def init(sequence): with open(argv[1]) as input: sequence = "".join([line.strip() for line in input.readlines()[1:]]) return sequence
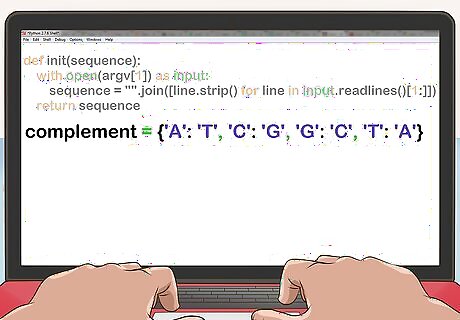
Create a hash table that maps each nucleotide to its complement. complement = {'A': 'T', 'C': 'G', 'G': 'C', 'T': 'A'}

Iterate through the sequence and use a hash table lookup to construct the complementary sequence. Reverse the resulting vector. def reverse_complement(seq): bases = [complement[base] for base in seq] bases = reversed(bases) return bases
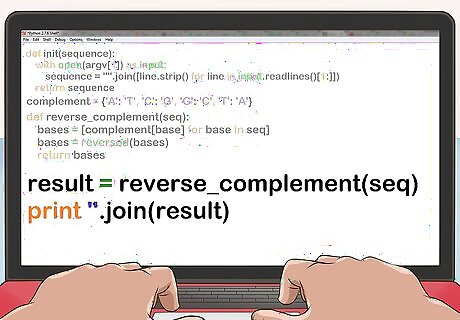
Print the contents of the vector.= result = reverse_complement(seq) print ''.join(result)


















Comments
0 comment